ARCHITECTURE
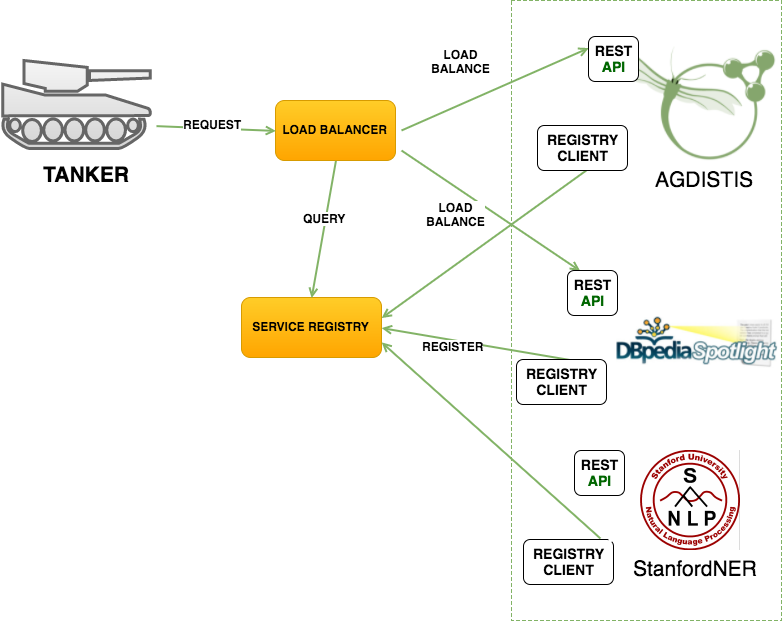
TANKER was designed with portability and efficiency in mind. It was also designed to be customizable and extensible w.r.t. its user interface, functionality and the integration of underlying components. The overall architecture of TANKER is shown in TANKER is built using a microservice architecture [9] . Microservices have been getting a lot of attention and popularity in the recent years 9 because of its significant benefits, especially w.r.t enabling the agile development, improving scalability, reliability and failure tolerance.
TANKER does not depend on any specific NERD service and is generic enough to be connected to any replacement microservice that abides by given service specification. This allows for simple configuration as well as adds a way to extend the functionality of the system - by adding or removing the microservices we can easily tailor the final user experience.
Additionally, microservices enforces a modularity level which is much faster to develop, and easier to understand and maintain. This architecture enables the development of each server independently by letting the architects free to choose appropriate technologies for different kind of problems. Thus, being possible to combine different programming languages in one single solution. The other components of TANKER are described in the sequence.
Scalability and Fault tolerance
Scalability is the capability to handle a growing amount of processes within a computational system in a graceful manner, providing minimal interruptions to ongoing operations. This feature is mandatory for enterprise systems in addition to fault-tolerance, scaling up mode and some others, to deliver a good user experience at a minimum cost.
Most of NERD solutions are usually developed under synchronous or asynchronous requests. Both requests wait for a response, however, the synchronous might block the user interaction while the asynchronous does not. Commonly, distributed applications consider services interactions to decide which one will be used in its ecosystem. For instance, in synchronous requests, HTTP REST or Thrift 10 are adopted, on the other hand, the Advanced Message Queuing Protocol 11 is used for asynchronous.
These request types infer on Inter-Process Communication (IPC) mechanisms. IPC software is a central piece of the architecture to ensure that microservices will scale and have fault-tolerance. This component is usually designed to be highly configurable and supports running in hybrid environments that are multi-region and multi-zone. To this end, TANKER supports synchronous interactions relying on Ribbon framework 12 as our IPC. Ribbon framework offers client-side software load balancing algorithms and a good set of configuration options such as connection timeouts and retry algorithms that fills in our requirements for NERD environments.
Configuration
The configuration of TANKER aims to reduce the complexity of management processes by using cloud services. Therefore, TANKER is based on Spring Cloud Config 13 which offers a client-side application for exposing configuration of a distributed system. It is integrated with Spring ecosystem, but it can also be used with any application running in any programming language. This service uses the human-readable data serialization language (YAML 14 ), a widely spread format to describe services parameters and exposes all of them under a REST/API (see Listing 1).
spring:
profiles: eureka primary
cloud:
config:
uri: http://localhost:8001
eureka:
instance:
preferIpAddress: true
enableSelfPreservation: false
client:
name: eureka
. . .Moreover, the delivered configuration through agnostic technologies will reinforce TANKER architecture pliability, by allowing approaches written in non-JVM technologies to reuse parameters and quickly integrate to the IPC.
Service Registry
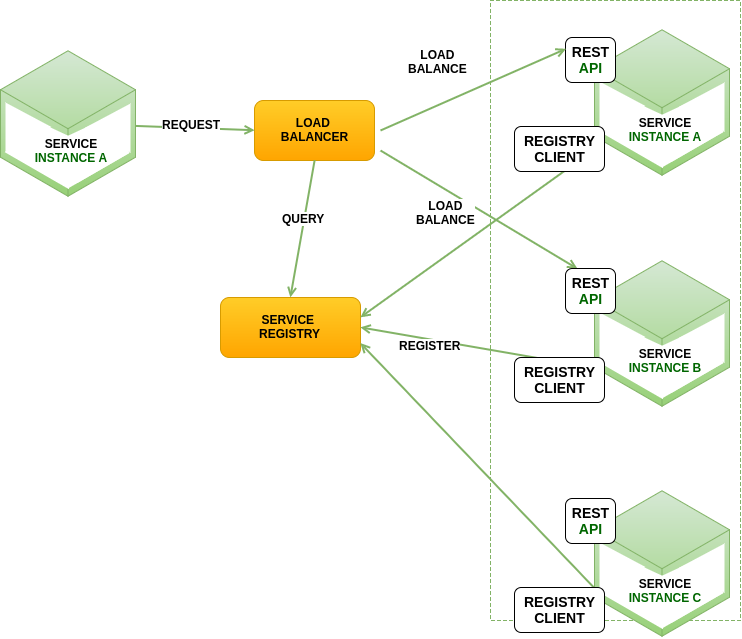
Distributed systems need to localize the network address of each service. Services assign network locations dynamically. Moreover, the set of services instances also changes periodically because of auto-scaling, failures, and upgrades. This reinforces the need to have an elaborated service framework that uses a discovery pattern.
There are two service registry patterns: client-side discovery and service-side discovery. In client-side discovery pattern, clients query the service registry to select an available resource and perform a request. In the server-side discovery pattern, clients make a request via router, which queries the service registry and forward the request to an available instance [1] .
TANKER uses Eureka 15 for service discovery. Eureka is a REST server-side discovery service that locates services for load balancing and fail over of middle-tier servers.
Completeness
TANKER architecture offers a pluggable platform that allows the whole community to interconnect a set of services and approaches, making it available into a powerful standardized API. To this end, TANKER comprises of scaffoldtechnique. This technique provides a basis configuration that allows a quick development by using parameters from our setup services and by connecting to our service registry infrastructure.