1 Introduction
In the last
decade, multimedia and, more particularly, video systems have benefited from a
tremendous research interest. The main reason for this is the increasing
ability computers now have for supporting video data, notably thanks to
unceasing improvements in data compression formats (as MPEG-4 and MPEG-7), in
networks transfer rates and operating systems [1], and in disk storage
capacity. Unsurprisingly, new applications have risen such as video on demand,
video conferencing and home video editing which directly benefit from this
evolution. Following this trend, research efforts ([2], [3]) have been made to
extend DataBase Management Systems (DBMS) so that they support video data types
not simply through Binary Large Objects (BLOB). Indeed, DBMS seem to be
well-suited systems for tackling problems posed by the video, namely storage,
modeling, querying and presentation. Video data types must be physically
managed apart from other conventional data types in order to fulfill their
performance requirements. Video modeling must take into account the
hierarchical structure of a video (shots, scenes and sequences) and allow
overlapping and disjoint segment clustering [4]. The video query language must
allow one to query video content using textual annotations or computed
signatures (color, shape, texture, ….) and deal with the dynamic (movements) of
objects in the scenes as well as with semi-structural aspects of videos and,
finally, must offer the possibility of creating new videos.
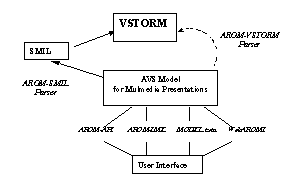
We have designed and implemented V-STORM [5] a video system which captures video data in an object DBMS. The V-STORM model considers video data from different perspectives (represented by class hierarchies): physical (as a BLOB), structural (a video is made up of shots which are themselves composed of scenes which can be split into sequences), composition (for editing new videos using data already stored in the database), semantics (through an annotation, a video segment is linked to a database object or a keyword). V-STORM uses and extends the O2 object DBMS and comes as a tool for formulating queries on videos, composing a video using the results of queries, and generating video abstracts. V-STORM can play videos (or segments of) of its database but also virtual videos (or segments of) composed through an O2 interface. Moreover, it is possible to use V-STORM as a multimedia player for presentations described using the SMIL [6] standard . This way, V-STORM can be classified in the family of multimedia presentation software like GriNS [7] or RealNetworks G2 [8].
We show
here how AROM [9], an object-based knowledge representation system, can be used
to help a V-STORM user to build, in a more declarative way, a multimedia
presentation by instantiating a knowledge base rather than by writing a SMIL
file. Then, we show how both spatial and temporal consistencies of multimedia
presentation can be maintained by AROM.
The paper is organized
as follows : sections 2 and 3 present respectively the V-STORM and AROM systems
; section 4 describes the AVS model, an AROM knowledge base which corresponds
to a general multimedia presentation structure ; section 5 gives the related
works before we conclude in section 6.
2 The V-STORM System
V-STORM differentiates between the raw video stored in the database and the video which is watched and manipulated by end-users. From a user point of view, a video is a continuous media which can be played, stopped, paused, etc. From a DBMS point of view, a video is a complex object composed of an ordered sequence of frames, each having a fixed display time. This way, new virtual videos can be created using frames from different segments of videos.
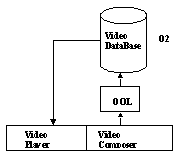
Figure 1. The
V-STORM architecture. Through the video composer interface, a video is
described by the user, translated in OQL so that its component video segments
can be sought in the O2 video database. Then, the video is played by the
V-STORM.
In V-STORM, the Object Query Language (OQL) [10] is used (see Figure 1) to extract video segments to compose virtual videos. Video query expressions are stored in the databases and the final video is generated at presentation time. This approach avoids data replication. A video query returns either a video interval which is a continuous sequence of frames belonging to the same video, or a whole video, or an excerpt of a raw video (by combination of the two previous cases), or a logical extract of a video stemming from various raw videos.
Video composition in V-STORM is achieved using a set of algebraic operators. This way a virtual video can be the result of the concatenation, or the concatenation without duplication (union), or the intersection, or the difference of two videos, or, as well, the reduction (by elimination of duplicate segments) or the finite repetition of a single video. Annotations in V-STORM are used to describe salient objects or events appearing in the video. They can be declared at each level of the video hierarchy. Annotations are manually created by the users through an annotation tool. V-STORM also integrates an algorithm to automatically generate video abstracts. Video abstracts aims at optimizing the time for watching a video in search of a particular segment. The user has to provide some information concerning the expected abstract: its source (one or more videos), its duration, its structure (which reflects the structure of the video), and its granularity (in the video segments might be more relevant than others). Finally, in order to open V-STORM to the multimedia presentation standardization, we have developed a SMIL parser (see Figure 2) so that V-STORM can read a SMIL document and play the corresponding presentation. Also, interactivity is possible since V-STORM handles the presence of anchors for hypermedia links during presentations.
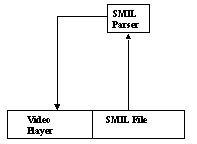
Figure 2. V-STORM
can also be used as multimedia presentation. The presentation is described in
SMIL, sent to a parser and played by the VSTORM video player.
The parser checks the validity of the SMIL document against the SMIL DTD (extended to support new temporal operations carried out by V-STORM). Then the different SMIL elements are translated in V-STORM commands and the video is displayed. Currently, this parser is limited and does not exploit all the V-STORM functionalities concerning operations on videos. The work presented here extends the description of a la SMIL multimedia presentations in order to better exploit V-STORM capabilities.
3
The AROM System
Object-Based
Knowledge Representation Systems (OBKRS) are known to be declarative systems
for describing, organizing and processing large amounts of knowledge. In these systems
[11], once built, a knowledge base (KB) can be exploited through various and
powerful inference mechanisms such as classification, method calls, default
values, filters, etc. AROM (which stands for Associating Relations and Objects
for Modeling) is a new OBKRS which departs from others in two ways. First, in
addition to classes (and objects) which often constitute the
unique and central representation entity in OBKRS, AROM uses associations (and tuples), similar to those found in UML [12], to describe and
organize links between objects having common structure and semantics. Second, in addition to the classical OBKRS inference mechanisms, AROM
integrates an algebraic modeling language (AML) for expressing operational
knowledge in a declarative way. The
AML is used to write constraints, queries, numerical and symbolic equations
involving the various elements of a KB.
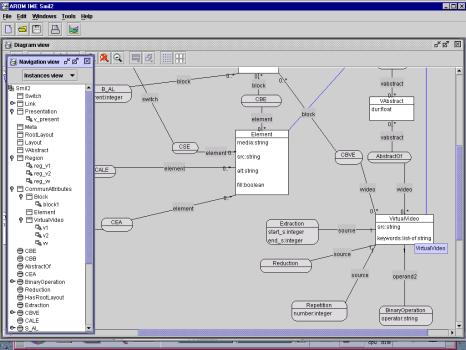
A class in AROM
describes a set of objects sharing common properties and constraints. Each
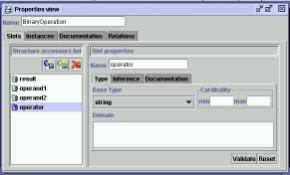
class is characterized by a set of properties called variables and by a set of constraints. A variable denotes a
property whose basic type is not a
class of the KB. Each variable is characterized by a set of facets (domain restriction facets,
inference facets, and documentation facets). Expressed in the AML, constraints
are necessary conditions for an object to belong to the class. Constraints bind
together variables of – or reachable from – the class. The
generalization/specialization relation is a partial order organizes classes in
a hierarchy supported by a simple inheritance mechanism. An AROM object
represents a distinguishable entity of the modeled domain. Each object is
attached to exactly one class
at any moment.
In AROM, like in UML,
an association represents a set of similar links between n (n ³ 2) classes, being distinct or not. A link
contains objects of the classes (one for each class) connected by the
association. An association is described by means of roles, variables and
constraints. A role corresponds to the connection between an association and
one of the classes it connects. Each role has a multiplicity, whose meaning is
the same as in UML. A variable of an association denotes a property associated
with a link and has the same set of available facets as a class variable. A tuple of an n-ary association having m
variables vi (1 £ i £ m)
is the (n+m)-uple made up of the n
objects of the link and of the m
values of the variables of the association. A tuple is an "instance"
of an association. Association constraints involve variables or roles and are
written in the AML, and must be satisfied by every tuple of the association.
Associations are organized in specialization hierarchies. See Figures 3 and 4
for a textual and a graphical sketches of an AROM KB dedicated to multimedia
presentations.
First introduced in
Operations Research, algebraic modeling languages (AMLs) make it possible to
write systems of equations and/or of constraints, in a formalism close to
mathematical notations. They support the use of indexed variables and expressions,
quantifiers and iterated operators like å (sum) and Õ (product), in
order to build expressions such as ![]() . AMLs have been used for linear and non-linear, for
discrete-time simulation, and recently for constraint programming [13]. In AROM,
the AML is used for writing both equations, constraints, and queries. AML
expressions are built from the following elements: constants, indices and
indexed expressions, operators and functions, iterated operators, quantified
expressions, variables belonging to classes and associations, and expressions
that allow to access to the tuples of an association. An AML interpreter solves
systems of (non-simultaneous) equations and processes queries. Written in Java
1.2, AROM is available as a platform for knowledge representation and
exploitation. It comprises an interactive modeling environment, which allows
one to create, consult, and modify an AROM KB; a Java API, an interpreter for
processing queries and solving sets of (non-simultaneous) equations written in
AML, and WebAROM, a tool for consulting and editing a KB through a Web browser.
. AMLs have been used for linear and non-linear, for
discrete-time simulation, and recently for constraint programming [13]. In AROM,
the AML is used for writing both equations, constraints, and queries. AML
expressions are built from the following elements: constants, indices and
indexed expressions, operators and functions, iterated operators, quantified
expressions, variables belonging to classes and associations, and expressions
that allow to access to the tuples of an association. An AML interpreter solves
systems of (non-simultaneous) equations and processes queries. Written in Java
1.2, AROM is available as a platform for knowledge representation and
exploitation. It comprises an interactive modeling environment, which allows
one to create, consult, and modify an AROM KB; a Java API, an interpreter for
processing queries and solving sets of (non-simultaneous) equations written in
AML, and WebAROM, a tool for consulting and editing a KB through a Web browser.
4
Coupling AROM and V-STORM
As mentioned above,
multimedia scenarios played by V-STORM can be described using SMIL. The
starting point of this study is twofold. We aim first at providing a UML-like
model in order to ease the description of a multimedia presentation and,
second, at reinforcing consistency regarding spatial and especially temporal
constraints between the components of a multimedia presentation. It is our conviction
that, SMIL like XML [14], are not intuitive knowledge representation languages,
and one needs to be familiar with their syntax before to read or write and
understand the structure of a document. So, we propose an AVS (AROM/V-STORM)
model (see Figures 3 and 4), which consists of an AROM knowledge base whose
structure incorporates any SMIL element used in the description of a multimedia
presentation. This way, we provide a V-STORM user with an operational UML-like
model for describing her multimedia presentation. Using an entity/relation (or
class/association) approach for modeling is now a widely accepted approach,
where UML has become a standard. Through the AROM Interface Modeling
Environment, the graphical representation of classes and associations which
constitute the AVS model, gives the user a more intuitive idea of the structure
of her presentation. Moreover, taking advantage of the AROM's AML and type
checking, the user can be informed about the spatial and temporal consistencies
of her presentation.
4.1
An AROM
Model for Multimedia Presentations
Since V-STORM can play
any presentation described with SMIL, our AROM model for multimedia
presentation is SMIL compliant. This means that it incorporates classes and
associations corresponding to every element that can be found in the structure
of a SMIL document. However, the
main objective of the AVS model is to give the user the opportunity to invoke
any kind of operations V-STORM can performed on a video.