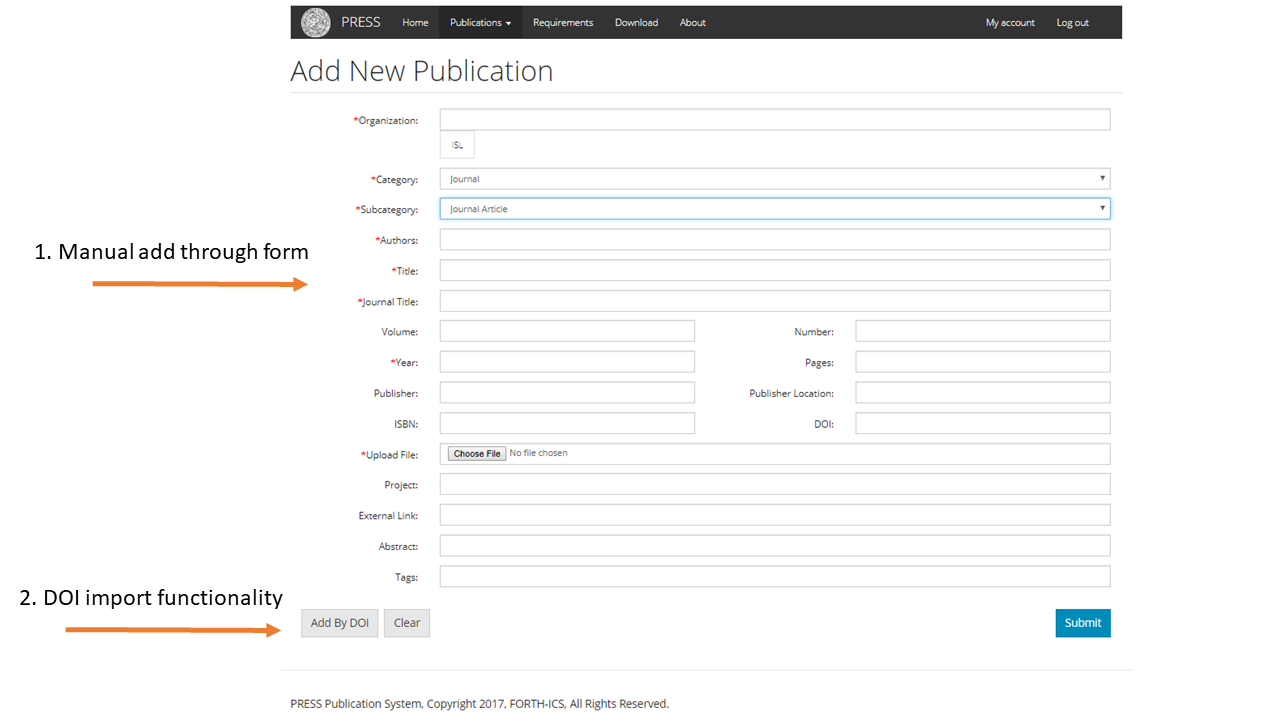
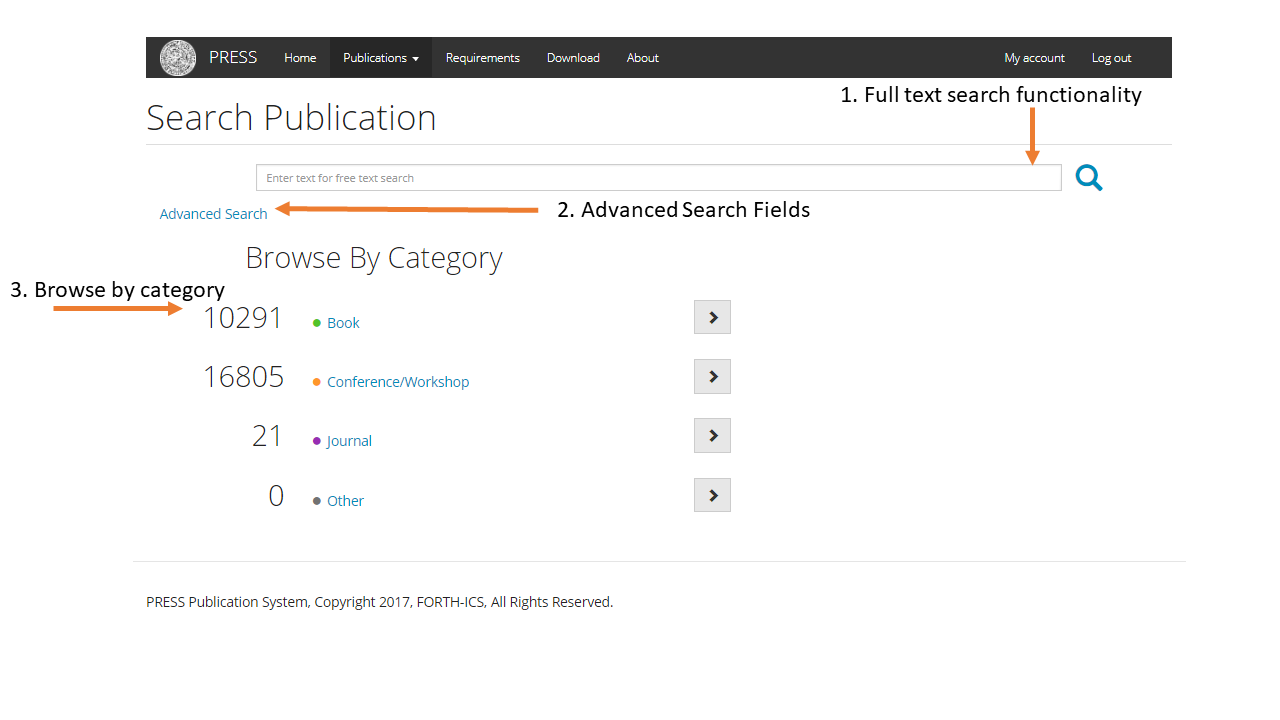
Methodology
Semantics
Semantic Web technology enables more sophisticated knowledge management, by applying evolving and refactoring schemas, metadata and relationships between them [3] . The flexibility of semantically enriched data gives rise to the implementation of efficient semantics-aware applications that can facilitate data integration, support knowledge enrichment and advanced query capabilities by searching between multiple patterns across the metadata.
Our system leverages such technologies by developing a basic ontology in OWL (called Press Ontology) which is CERIF compatible and captures the core schema containing basic entities that are related with each publication, and their respective properties and relationships. The ontology (see Figure 1 ) consists of 6 top classes, 4 main (Publication, Person, Laboratory and Project) and 2 complementary ones (List, List_Slot). The latter are used for keeping the sequence on items following the approach of [4] . Classes are connected through 7 object properties that denote their relationships. We use 47 data properties to cover all attributes of a publication.
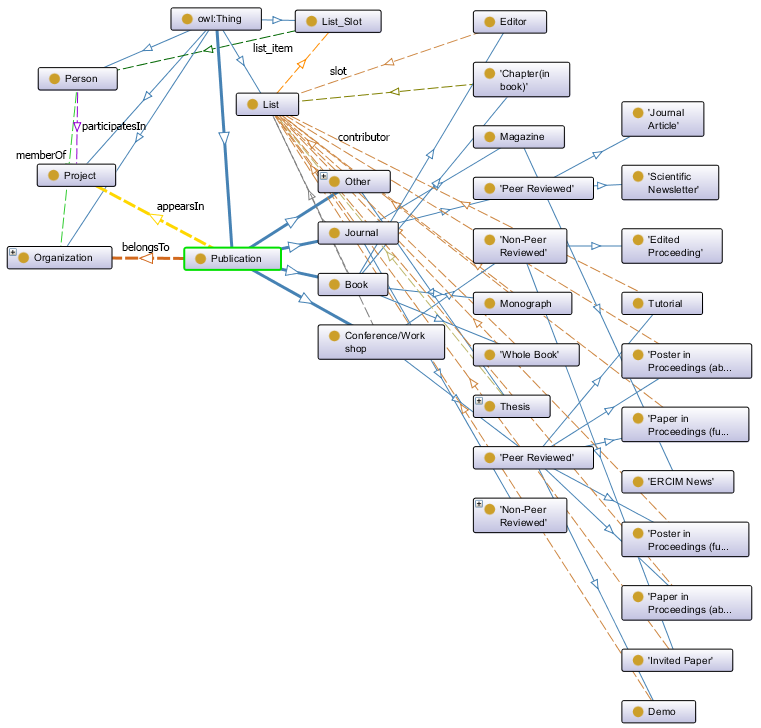
The Publication class contains 4 direct subclasses and various indirect ones, representing different publication types (e.g., Book, Conference/Workshop etc). Different properties are used to connect publications to their authors (a property to the Person Class), authors’ affiliations (property to Organization) and projects that funded the work (property to Project Class). We use the FOAF ontology 12 for Person entities. Finally, the PRESS ontology provides features like keeping the order of authors, distinguishing peer reviewed from non-peer reviewed publications, better query evaluation based on indirect classes classification and a small but comprehensive schema. For each publication we store metadata information as RDF triples to the Blazegraph 13 repository which is an ultra-scalable, open-sourced, high-performance graph database which can store up to 50B triples/quads. It is a plug and play cross-platform software, which also provides a REST API with an embedded endpoint for enabling SPARQL query functionalities.
Architecture
For the basic functionalities of PRESS we chose Drupal 14 , a robust CMS with a large established community that enables scalable development of web modules. PRESS can be conceptually divided into four main groups for the installed modules plus one for our developed module (see Figure 2 ). All modules communicate with each other independently of their conceptual group since they are built with the same Web Programming technologies. The first group deals with the User Authentication containing modules for leveraging security to the system. The second group ( UI Modules ) is related with modules necessary for the User Interface development. The third group consists of Back-End modules which are necessary for the unique identification and storing of each publication, enabling search engine optimization and sharing of external libraries. The core drupal functionalities are provided by the default Core Modules group. Finally, the drupal module that we implemented (named Publication Module ) creates one page per publication, and displays all the relevant information that can be edited later by each author.
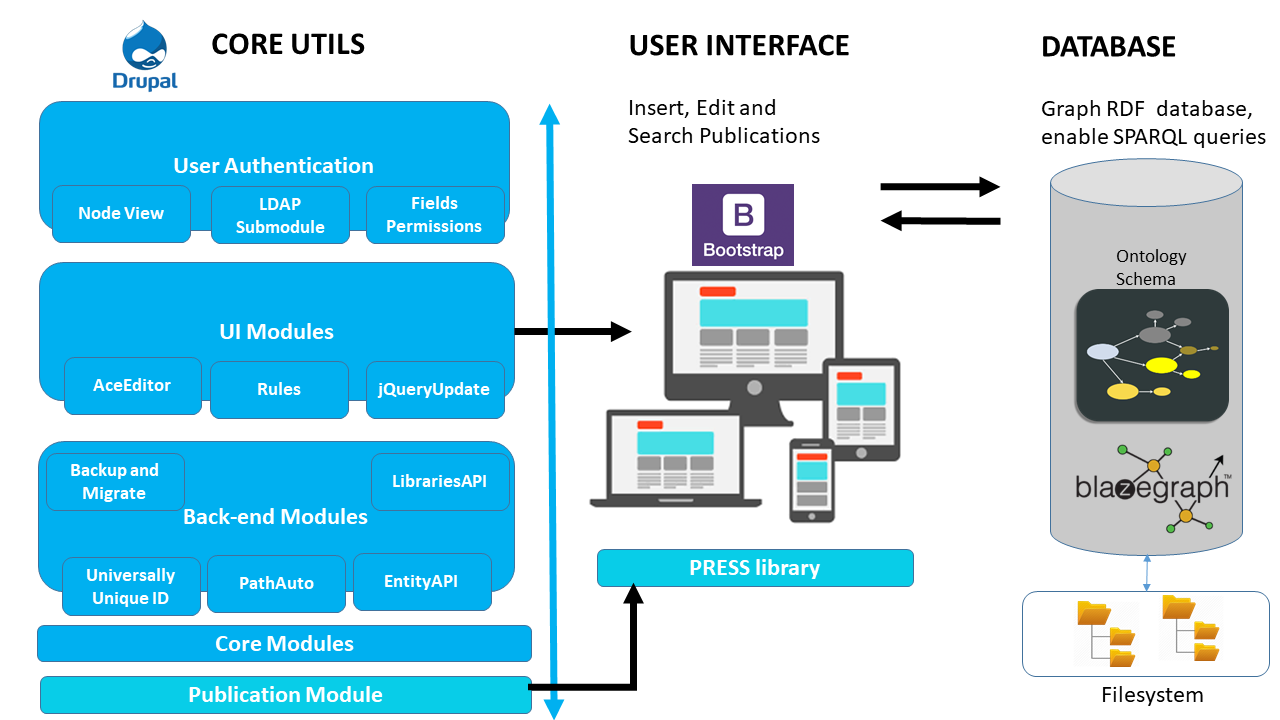
Also, we developed a library ( PRESS library ) that deals with the basic user interfaces for inserting, editing or searching for any publication exploiting the core UI modules and the publication module. Finally, the actual document of publication is stored as a pdf file in the file system of the webserver, exploiting the core modules of Drupal. Our architecture is loosely-coupled. Thus, we can replace existing modules (e.g., user authentication), interfaces (e.g. search interface), or even the ontology schema with alternative implementations without jeopardizing data consistency. All data is accessible through a public SPARQL endpoint.
Features and Innovation
The core innovative feature of PRESS is its advanced query capabilities. For example, it supports full free text queries by using the extended RDF predicate bds:search of SPARQL, as it has been implemented in Blazegraph. Moreover, with SPARQL, we can make complex and expressive queries upon RDF/OWL metadata, such as cross snapshot queries, range queries on dates etc. The use of Blazegraph Repository ensures scalability and stability [5] for the storing of all semantic information. Another advantage of PRESS is that it is open-source, cross platform, web-based and requires low resources to run [8] . It is extensible and currently integrated with Drupal CMS. In addition, a core design decision was for the system to be usable by all kinds of users, and not just experienced ones (i.e. librarians). Towards this end, we support a responsive and user-friendly interface, a basic security policy, import/export facilities (using DOI) and search engine optimization techniques. To the best of our knowledge there is no other semantic-aware open-source publication system that can provide all the above functionalities.